
In the increasingly digital landscape, data privacy has become a paramount concern for individuals and organizations alike. The need to understand how user data is collected, processed, and utilized has sparked widespread discussion. This article addresses one of the more complex aspects of this challenge: privacy-preserving attribution. As businesses strive to measure the effectiveness of their marketing campaigns and understand user behavior, they must do so while upholding stringent data protection standards. Understanding the principles behind privacy-preserving attribution is no longer optional, it is essential for maintaining user trust and complying with evolving global regulations.
This article, “Navigating the Future of Data Privacy: A Clear Explanation of Privacy-Preserving Attribution,” aims to demystify this critical concept. We will explore the core principles of privacy-preserving attribution, examining various methodologies and technologies that enable marketers to gain valuable insights without compromising user privacy. We will delve into the challenges and opportunities presented by this emerging field, providing a clear and concise overview for readers from all backgrounds, whether they are seasoned data scientists or simply interested in learning more about data privacy in the modern world. The discussion includes examples of privacy-preserving techniques utilized globally.
Understanding the Fundamentals of Privacy-Preserving Attribution
Privacy-Preserving Attribution (PPA) represents a paradigm shift in digital marketing and advertising, moving away from traditional methods that heavily rely on individual user data. At its core, PPA aims to accurately measure the impact of marketing efforts while safeguarding user privacy.
Traditional attribution models often involve tracking users across different platforms and touchpoints, raising significant privacy concerns. PPA addresses these concerns by employing techniques that minimize the collection and use of personally identifiable information (PII).
The foundational principle of PPA lies in analyzing aggregated and anonymized data. Instead of tracking individual user journeys, PPA methods focus on identifying patterns and trends within larger datasets to infer the effectiveness of various marketing channels. This approach allows businesses to understand the customer journey without compromising the privacy of individual users.
In essence, PPA enables businesses to make informed decisions about their marketing strategies while adhering to increasingly strict data privacy regulations and respecting user preferences for privacy.
The Evolution of Attribution in a Privacy-Focused World
The landscape of marketing attribution has undergone a significant transformation in recent years, driven primarily by growing concerns over user privacy and stricter data protection regulations such as GDPR and CCPA. Traditional attribution methods, which often relied on tracking individual users across various touchpoints, are becoming increasingly untenable.
Initially, attribution models operated in a relatively unrestricted data environment. This allowed for detailed user profiling and precise tracking of customer journeys. However, the emphasis on privacy-centric approaches has forced a shift towards techniques that minimize data collection and prioritize user anonymity.
This evolution has led to the development and adoption of privacy-preserving attribution methods. These techniques aim to provide valuable insights into marketing effectiveness while adhering to ethical and legal requirements for data protection. The focus is now on aggregating data and using anonymization techniques to understand overall trends rather than tracking individual users. The development of new technology to support a new way to attribute has been increasing in the past few years.
Key Techniques Used in Privacy-Preserving Attribution Methods
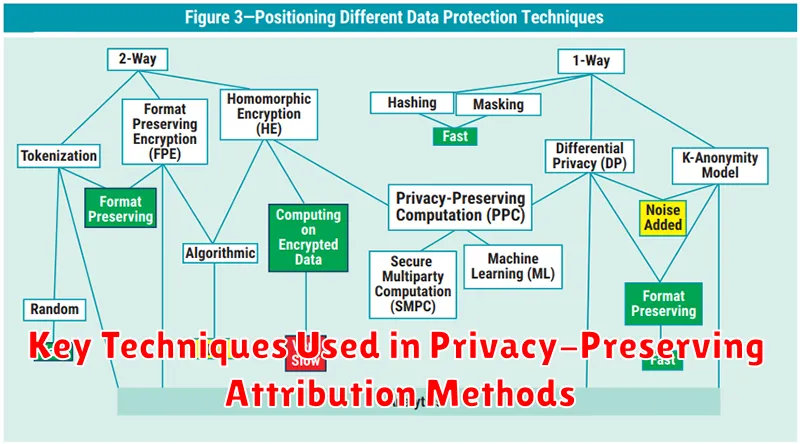
Privacy-preserving attribution relies on several core techniques to analyze data while protecting individual user privacy. These techniques aim to minimize the risk of re-identification and comply with increasingly stringent data privacy regulations like GDPR and CCPA. Here are some key approaches:
- Differential Privacy (DP): Adds calibrated noise to the data or query results to obscure individual contributions while still allowing for accurate aggregate analysis.
- Federated Learning (FL): Enables model training on decentralized datasets residing on users’ devices or in separate data silos, without directly accessing or sharing the raw data.
- Secure Multi-Party Computation (SMPC): Allows multiple parties to jointly compute a function over their private inputs without revealing those inputs to each other.
- Homomorphic Encryption (HE): Enables computations to be performed on encrypted data without decrypting it first, ensuring data confidentiality throughout the attribution process.
- K-Anonymity: Modifies data to ensure that each record is indistinguishable from at least *k* other records, thus limiting the ability to identify individuals.
The specific choice of technique depends on the sensitivity of the data, the desired level of privacy, and the computational resources available.
Benefits of Adopting Privacy-Preserving Attribution for Your Business
Implementing privacy-preserving attribution offers significant advantages for businesses operating in today’s data-conscious landscape. Primarily, it builds and strengthens customer trust. By demonstrating a commitment to protecting user data, you foster a more positive brand image and encourage continued engagement.
Furthermore, adopting these methods allows you to maintain effective marketing measurement in the face of increasingly stringent privacy regulations like GDPR and CCPA. This ensures continued insights into campaign performance while remaining compliant.
Another key benefit is gaining a competitive advantage. Businesses that prioritize privacy are often viewed favorably by consumers and partners, leading to increased opportunities and stronger collaborations.
Finally, privacy-preserving attribution reduces the risk of data breaches and associated liabilities, minimizing potential reputational damage and financial penalties. This contributes to a more secure and sustainable business model.
Comparing Privacy-Preserving Attribution Models: Which is Right for You?
Selecting the appropriate privacy-preserving attribution model is crucial for accurately measuring marketing effectiveness while upholding user privacy. Several models exist, each with unique strengths and weaknesses.
Key Considerations
When evaluating models, consider the following:
- Accuracy: How closely does the model reflect actual user behavior?
- Privacy Guarantees: What level of privacy protection does the model offer (e.g., differential privacy)?
- Scalability: Can the model handle large datasets and complex marketing campaigns?
- Implementation Complexity: How difficult is it to implement and maintain the model?
Popular Models
Common models include:
- Differential Privacy-based models: Add noise to data to protect individual privacy.
- Federated Learning models: Train models across decentralized devices.
- Secure Multi-party Computation (SMC) models: Enable collaborative computations without revealing raw data.
The best model depends on your specific business needs, data availability, and risk tolerance. A thorough assessment of each model’s characteristics is essential for making an informed decision.
How Differential Privacy Enhances Data Security in Attribution
Differential privacy (DP) is a rigorous mathematical framework that adds statistical noise to data, thereby ensuring individual privacy while still enabling accurate aggregate analytics. In the context of attribution, DP plays a crucial role in protecting user data from re-identification.
Specifically, DP ensures that the inclusion or exclusion of any single individual’s data in a dataset does not significantly alter the outcome of any analysis. This is achieved by injecting calibrated noise, typically following a Laplace or Gaussian distribution, into the attribution calculations.
By implementing DP, organizations can confidently perform attribution analyses without compromising user privacy. This approach allows for valuable insights into marketing effectiveness while adhering to stringent data protection standards and regulations. The level of privacy guaranteed by DP is quantified by a privacy budget, typically denoted by ε (epsilon) and δ (delta), representing the trade-off between privacy and accuracy. Smaller values of ε and δ indicate stronger privacy guarantees but may result in lower accuracy.
The Role of Federated Learning in Privacy-Preserving Measurement
Federated Learning (FL) plays a crucial role in privacy-preserving measurement by enabling collaborative model training without direct data sharing. This distributed approach allows algorithms to learn from decentralized datasets residing on users’ devices or isolated servers.
Instead of aggregating raw data into a central location, FL involves:
- Training a local model on each participating device or server.
- Sending only the model updates (e.g., gradients) to a central server.
- Aggregating these updates to create a global model.
- Distributing the improved global model back to participants for further local training.
This process is repeated iteratively, refining the global model while keeping individual data private. By minimizing data exposure, Federated Learning significantly reduces the risk of privacy breaches and enhances compliance with data protection regulations, making it a powerful tool in privacy-preserving attribution and other measurement applications.
Addressing Common Misconceptions About Privacy-Preserving Attribution
Despite growing adoption, several misconceptions surround privacy-preserving attribution (PPA). Addressing these misunderstandings is crucial for informed decision-making and effective implementation.
One common misconception is that PPA renders marketing attribution entirely ineffective. In reality, PPA allows for aggregate insights while protecting individual user data. It shifts the focus from individual-level tracking to cohort-based analysis.
Another misconception is that PPA is overly complex and requires significant technical expertise. While some methods can be intricate, user-friendly solutions are emerging, making PPA more accessible to businesses of all sizes. Furthermore, many platforms offer managed PPA services, reducing the technical burden.
Finally, some believe that PPA provides absolute and impenetrable privacy. It’s important to understand that PPA techniques aim to minimize privacy risks, not eliminate them entirely. Implementing a layered approach to data protection, including PPA, remains essential.
Real-World Applications of Privacy-Preserving Attribution
Privacy-preserving attribution (PPA) is finding practical applications across diverse sectors. In e-commerce, it enables the measurement of ad campaign effectiveness without exposing individual user data. This allows retailers to optimize their marketing spend while adhering to stringent privacy regulations.
In the financial services industry, PPA facilitates the analysis of customer behavior across different touchpoints, such as mobile apps and websites, without compromising sensitive financial information. This helps financial institutions personalize their services and detect fraud more effectively.
Healthcare organizations are leveraging PPA to understand the impact of digital health initiatives on patient outcomes while maintaining patient confidentiality. This is crucial for evaluating the success of telemedicine programs and health awareness campaigns.
Even in social media, PPA is being used to analyze the spread of information and identify influential users without revealing individual identities. This helps platforms understand user behavior trends while protecting user privacy. These examples showcase the growing importance and adaptability of PPA in various industries.
Future Trends and Developments in Privacy-Preserving Attribution

The field of privacy-preserving attribution is rapidly evolving, driven by increasing consumer awareness and stricter regulations. Several key trends are shaping its future:
- Advanced Cryptographic Techniques: Expect to see increased utilization of homomorphic encryption and secure multi-party computation (SMPC) to enable more complex attribution models without revealing individual user data.
- Integration with AI and Machine Learning: Future attribution models will leverage AI to improve accuracy and efficiency while maintaining privacy. This includes using differential privacy to train machine learning models on aggregated data.
- Standardization and Interoperability: Efforts are underway to create industry standards for privacy-preserving attribution, fostering interoperability between different platforms and solutions.
- Focus on User-Centric Privacy: Future developments will prioritize user control and transparency, empowering individuals to manage their data and preferences related to attribution.
These advancements will enable businesses to gain valuable insights from their marketing efforts while upholding the highest standards of data privacy.
{kind=link}