
In today’s data-driven world, organizations are increasingly reliant on data to gain insights, improve services, and drive innovation. However, the collection and use of data raise significant concerns about privacy. To address these concerns and comply with evolving regulations like GDPR and CCPA, two common techniques are employed: data anonymization and pseudonymization. Understanding the nuances between these methods is crucial for any organization seeking to balance the benefits of data utilization with the imperative of protecting individual privacy.
This article delves into the critical distinction between data anonymization and pseudonymization. We will explore the technical differences between these approaches, examining how each method transforms data to reduce the risk of identification. Furthermore, we will analyze the strengths and weaknesses of each technique in various contexts, including the legal and ethical considerations involved in choosing the appropriate method for protecting sensitive information while still allowing for valuable data analysis and research. A clear understanding of these concepts is vital for navigating the complex landscape of data privacy in the modern era.
Understanding Data Privacy: A Primer
Data privacy, also known as information privacy, revolves around the appropriate handling of data, particularly personal data. It encompasses the right of individuals to control how their personal information is collected, used, and shared. Effective data privacy practices are essential for building trust with individuals and adhering to legal and ethical standards.
Key components of data privacy include:
- Confidentiality: Protecting data from unauthorized access and disclosure.
- Integrity: Maintaining the accuracy and completeness of data.
- Availability: Ensuring that authorized users have access to data when needed.
Various legal frameworks, such as GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act), emphasize the importance of data privacy and impose stringent requirements on organizations that collect and process personal data. Understanding these frameworks is crucial for navigating the complexities of data protection.
What is Data Anonymization? Techniques and Considerations
Data anonymization is the process of irreversibly altering data in such a way that it can no longer be attributed to a specific individual. The goal is to remove all personally identifiable information (PII), making it impossible to re-identify the data subject, even with additional information.
Several techniques are employed in data anonymization, including:
- Suppression: Removing specific data elements.
- Generalization: Replacing precise values with broader categories (e.g., age ranges instead of exact age).
- Masking: Obscuring data with random characters or values.
- Aggregation: Combining data points to create summaries.
When considering anonymization, it’s crucial to assess the risk of re-identification. Even after applying anonymization techniques, sophisticated methods and access to external data sources might still pose a threat. A robust anonymization strategy involves a thorough risk assessment and ongoing monitoring to ensure the continued protection of privacy.
What is Data Pseudonymization? A Practical Approach
Data pseudonymization involves replacing directly identifying information with pseudonyms, which are artificial identifiers. This process aims to de-identify data without completely eliminating the possibility of re-identification.
Unlike anonymization, pseudonymized data can be linked back to the original data subject using additional information, typically stored separately and securely. This makes it a reversible process.
A practical approach to pseudonymization often involves techniques such as:
- Tokenization: Replacing sensitive data with non-sensitive substitute values (tokens).
- Encryption: Encrypting identifiers with a key, making them unreadable without the key.
- Hashing: Transforming data into a fixed-size string of characters using a one-way function.
The key to successful pseudonymization is to maintain a strong separation between the pseudonymized data and the re-identification key. This ensures that the data remains protected while allowing for certain types of analysis and processing.
Key Differences Between Data Anonymization and Pseudonymization

The core difference between data anonymization and pseudonymization lies in the reversibility of the process. Anonymization aims to completely and irreversibly strip data of all personally identifiable information (PII), making it impossible to re-identify the data subject. Pseudonymization, on the other hand, replaces identifying information with pseudonyms or identifiers. While it obscures the original data, it allows for potential re-identification under specific conditions, such as using additional information held separately.
Here’s a concise breakdown:
- Reversibility: Anonymization is irreversible; pseudonymization is reversible.
- Re-identification Risk: Anonymization eliminates re-identification risk; pseudonymization reduces it, but does not eliminate it.
- Data Utility: Anonymized data often has lower utility than pseudonymized data due to the extensive data modification.
- Compliance: The compliance requirements differ, with anonymization sometimes offering exemption from certain data protection regulations, which is less likely with pseudonymization.
Use Cases for Data Anonymization
Data anonymization finds its application in scenarios where data utility is less critical than absolute privacy. It’s typically employed when organizations need to release or share data publicly, ensuring no individual can be re-identified.
One significant use case is in research. Anonymized patient data can be used in medical studies to identify trends and improve treatments without compromising patient confidentiality. Similarly, in academic research, survey responses can be anonymized to allow for statistical analysis and public sharing of findings.
Another crucial application is in open data initiatives. Governments and organizations release anonymized datasets to the public for transparency and to foster innovation. Examples include anonymized traffic data for urban planning or anonymized energy consumption data for developing energy-efficient solutions.
Finally, data archiving often involves anonymization. When data is stored for long-term preservation but its direct use is unlikely, anonymization ensures continued compliance with privacy regulations.
Use Cases for Data Pseudonymization
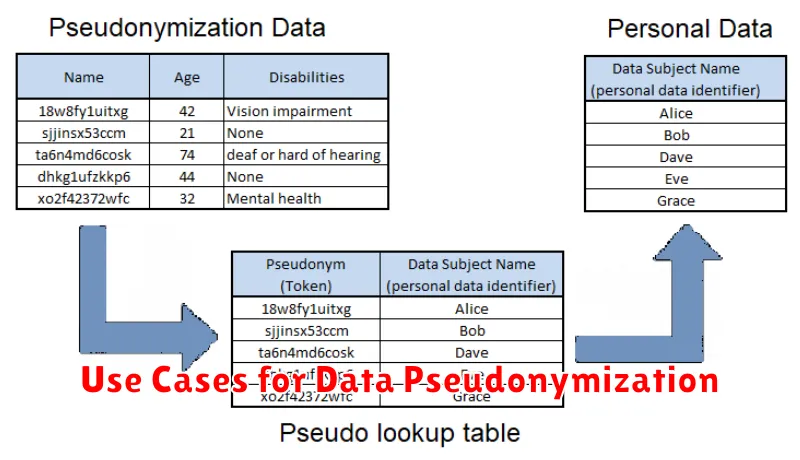
Data pseudonymization finds application in a wide array of scenarios where maintaining a degree of identifiability is necessary or beneficial, while still safeguarding privacy.
Medical Research
In medical research, pseudonymization allows researchers to track patient outcomes over time without directly identifying individuals. This is crucial for longitudinal studies and for monitoring the effectiveness of treatments.
Marketing and Advertising
The advertising industry uses pseudonymization to personalize marketing campaigns. By assigning pseudonyms to user profiles, companies can target ads based on interests and behaviors without accessing personally identifiable information (PII).
Data Analytics
Organizations utilize pseudonymization for data analytics to gain insights from large datasets. This enables them to identify trends and patterns while minimizing the risk of exposing sensitive data.
Customer Relationship Management (CRM)
CRM systems often employ pseudonymization to protect customer data while still allowing businesses to manage customer interactions and personalize services.
Software Development and Testing
Pseudonymized data is valuable in software development and testing environments. Developers can use realistic data to test applications without exposing actual user data.
Advantages and Disadvantages of Data Anonymization
Data anonymization offers significant advantages in privacy protection. Once data is effectively anonymized, it falls outside the scope of many data protection regulations, such as GDPR, because it’s no longer considered personal data. This allows for unrestricted data sharing and analysis without the need for individual consent.
Furthermore, anonymized data can be used for a wide range of research and development purposes, fostering innovation and scientific advancement. It simplifies data governance and reduces the risk of data breaches leading to the exposure of sensitive personal information.
However, data anonymization also has its drawbacks. The primary disadvantage is the potential loss of data utility. The process of removing or masking identifiers can reduce the richness and granularity of the data, limiting its analytical value. There’s also the risk of re-identification, especially with advancements in data analysis techniques and the availability of auxiliary datasets. If anonymization is not performed correctly, individuals might be re-identified, leading to serious privacy breaches. Finally, the irreversible nature of anonymization means that any future need to link the data back to individuals is impossible.
Advantages and Disadvantages of Data Pseudonymization
Data pseudonymization offers a balance between data utility and privacy protection. It involves replacing identifying information with pseudonyms, allowing data analysis while reducing the risk of direct identification.
Advantages of Data Pseudonymization
- Enhanced Data Utility: Enables a wide range of data analysis and processing activities.
- Improved Privacy: Reduces the risk of directly identifying individuals.
- Regulatory Compliance: Facilitates compliance with data protection regulations like GDPR.
- Data Sharing: Makes data sharing easier and safer for research or collaboration.
Disadvantages of Data Pseudonymization
- Re-identification Risk: Pseudonymized data can potentially be re-identified, especially with additional data sources or sophisticated techniques.
- Management Overhead: Requires careful management of pseudonyms and associated data.
- Complexity: Implementing and maintaining pseudonymization techniques can be complex.
- Not a Complete Solution: While it greatly reduces the risk, pseudonymization alone may not guarantee absolute privacy.
Choosing the Right Approach: Anonymization or Pseudonymization?
Selecting between data anonymization and pseudonymization hinges on the specific needs of the project and the acceptable level of risk. Anonymization is appropriate when the data is no longer needed for individual-level analysis and the primary goal is to protect privacy permanently. It is ideal when the risk of re-identification must be minimized.
Pseudonymization is more suitable when the data needs to be analyzed at the individual level, such as for research or personalized services, and when reversibility is required under certain circumstances (e.g., auditing, data correction). This approach allows for data linkage and analysis while reducing the risk of direct identification.
Consider the following questions to guide your decision:
- What is the purpose of the data processing?
- What level of identifiability is acceptable?
- Is it necessary to re-identify individuals in the future?
- What are the legal and ethical requirements?
A thorough assessment of these factors will help determine which technique best balances privacy protection with data utility.
Compliance and Legal Considerations for Data Anonymization and Pseudonymization
When implementing data anonymization or pseudonymization, organizations must carefully consider relevant compliance and legal frameworks. These frameworks often dictate the permissible uses of data and the required level of privacy protection.
Key regulations such as the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA) in the United States, and other national and regional laws impact how data can be processed. Under GDPR, for example, anonymized data is generally outside the scope of the regulation, while pseudonymized data remains personal data and is subject to its provisions.
It’s crucial to understand the specific definitions and requirements of each applicable law. Failure to comply can result in significant penalties and reputational damage. A Data Protection Impact Assessment (DPIA) may be necessary to evaluate the risks associated with data processing activities involving either anonymization or pseudonymization.
{kind=link}